MLOps и production в DS исследованиях
Репозиторий курса “MLOps и production в DS исследованиях 3.0”
Документацию проекта в удобном для изучения виде смотрите на Gitlab Pages — обновление сайта синхронизировано с обновлением репозитория.
Инструментарий
Детально см. в contributing.md
Методология ведения репозитория
Репозиторий используется для задач DS и MLOps одновременно, поскольку задания курса тесно интегрированы и [выглядящее более оптимальным] разделение на независимые репозитории исследователя и дата инженера в данный момент нецелесообразно. Если такое разделение будет сделано в дальнейшем, то взаимные перекрестные ссылки будут добавлены.
Задание по Docker
Зафиксированы зависимости при помощью poetry, созданы две среды main и dev (см. pyproject.toml). При сборке образа из Dockerfile используются зависимости только из main среды (main = production). Сборка и запуск контейнера:
docker build -t hello-mlops .
docker run -p 8080:80 -d hello-mlops
Приложение hello.py является простейшим тестом и выводит “Hello, MLOps!” в браузер.
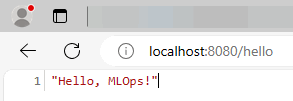{kind=link}
Задание CI/CD, исследование данных и документирование проекта
Выполнен линтеринг и валидация типов (ruff, mypy) в пайплайне lint-ci.yml. Дополнительно к заданию добавлены тесты pytest (см. test_hello.py) в пайплайне test-ci.yml.
Выполнена сборка и публикация проекта в виде пакета PyPi. Пайплайн в файле pypi-ci.yml. Пакет опубликован в Gitlab Pypi Registry.
Выполнена DinD сборка Docker образа. Пайплайн в файле dind-ci.yml. Образ опубликован в Gitlab Docker Registry.
Проведено разведочное исследование датасета из задания. Исследование по разделам и результаты в ноутбуке tree-data-research.ipynb
Выполнена сборка документации проекта в вебсайт при помощи Quarto (включая ноутбук с исследованием). Пайплайн в файле pages-ci.yml. Сайт опубликован на Gitlab Pages.
Итоговый отчет на странице Исследование.
Задание Snakemake
Реализован следующий worlkflow (см. Snakefile):
Препроцессинг данных, объединяющий csv-файлы в папках поочередно по шаблонам:
data/01/*.csv,data/02/*.csv,data/03/*.csv.Сформированный датасет подавался на вход скрипта trees-training-workflow.py с демонстрационным обучением ML-модели. Каждый запуск скрипта сгенерировал и сохранил артефакты с результатами.
Пайплайн Snakemake запускался с использованием виртуальной среды conda с пакетами Scikit-learn, Tensorflow и зависимостями. Команды подготовки среды и запуска:
conda env export -n ml -f .envs/ml.yml
snakemake --use-conda --conda-prefix ./.envs --cores 4
Итоговый отчет на странице Workflow.
Задание Hydra
Реализовано применение фреймворка Hydra. Файл конфигурации config.yaml включает несколько групп параметров: пути к данным и артефактам, файл с данными, параметры для ML-модели. Конфигурация и скрипты также поддерживают указание количества используемых ядер процессора, получаемое из переменной среды NUM_CORES.
ML-скрипт trees-training-multirun.py запускался в режиме multirun с перебором групп параметров:
python src/trees-training-multirun.py -m params.batch_size=32,64Ноутбук trees-training-getparams.ipynb для демонстрации взаимодействия с фреймворком через Compose-API
Итоговый отчет на странице Hydra.
Задание DVC
Реализован пайплайн в dvc.yaml для воспроизведения цепочки машинного обучения с версионированием данных, моделей, экспериментов и артефактов. Пайплан включает следующие стадии (шаги):
- Подготовка сырых данных (срез из датасета)
- Разделение данных на тренировочную и тестовую выборки
- Векторизация TF/IDF для обеих выборок
- Тренировка ML-модели логистической регрессии
- Предсказание результатов на тестовой выборке
Также обеспечен результат воспроизводимости пайплайна как локально, так и в CI/CD.
Итоговый отчет достаточно объемный и размещен на отдельной странице DVC.
Задание LakeFS
Подготовлен Docker compose образ, включающий сборку LakeFS, minIO (AWS S3 эмулятор) и БД Postgres.
Реализован Workflow пайплайн с использованием фреймворка Snakemake, демонстрирующий загрузку и версионирование датасета “NY 2015 street tree centus tree data”.
Итоговый отчет на странице LakeFS.
Задание MLflow
Применен базовый функционал MLflow в задаче версионирования эксперимента для двух различных ML-моделей. Выполнялась сравнительная задача машинного обучения по классификации отзывов из датасета Amazon reviews (оценка сентимента).
Добавлены ноутбуки с исследованиями:
- Модель №1: Частотный анализ на базе TF-IDF
- Модель №2: Эмбеддинг на базе Bert Transformer
Для выполнения задачи был запущен локальный MLflow инстанс, проведен сравнительный эксперимент для выбранных моделей, зафиксированы результаты и составлен отчет. Модель Bert по всем метрикам показала лучшие результаты.
Итоговый отчет на странице MLFlow.
Задание ClearML
Применен базовый функционал ClearML в задаче версионирования эксперимента для двух различных ML-моделей. Выполнялась сравнительная задача машинного обучения по классификации отзывов из датасета Amazon reviews (оценка сентимента).
Добавлены ноутбуки с исследованиями:
- Модель №1: Частотный анализ на базе TF-IDF, ссылка на эксперимент TF-IDF
- Модель №2: Эмбеддинг на базе Bert Transformer, ссылка на эксперимент Bert
Для выполнения задачи использовалась облачная SaaS-версия ClearML. Были проведены сравнительные эксперименты для выбранных моделей, зафиксированы результаты и составлен данный отчет. Модель Bert по всем метрикам показала лучшие результаты.
Итоговый отчет на странице ClearML.
Развертывание модели машинного обучения
Разработано приложение для анализа сентимента входного текста с использованием FastAPI, Celery, Redis и RabbitMQ.
Приложение предоставляет асинхронное высоконагруженное API для взаимодействия с моделью машинного обучения. В примере используется предобученная модель Трансформер для предсказания сентимента для входного текста, однако может быть использована любая ML-модель, т.к. скелет приложения является универсальным.
Приложение является самостоятельным “проектом-в-проекте”. Приоритетная поддерживаемая версия размещена в отдельном репозитории “ML Service with FastAPI, Celery, Redis and RabbitMQ”.
Итоговый отчет на странице FastAPI.
Задание Streamlit
Написано фронтенд веб-приложение чат-бота app.py с использованием фреймворка Streamlit. Приложение предназначено для предсказания сентимента во входных текстах, которые пользователь отправляет в диалог с чат-ботом.
Бэкенд реализован в виде отдельного REST API сервиса, использующего готовую ML-модель Трансформер. Бэкенд размещен в отдельном репозитории и может быть развернут локально или на любой подходящей для инференса платформе.
Итоговый отчет на странице Streamlit.
Задание Kubernetes
Развернут простой Kubernetes кластер на Minikube. Кластер включает:
- ConfigMap с конфигурацией Nginx и содержимым файла index.html
- Deployment с двумя репликами подов простого веб-приложения на базе образа Nginx
- Service, выполняющий роль балансировщика, и отправляющий трафик на поды
Итоговый отчет на странице Kubernetes.
Задание Feature Store
Развернут локальный инстанс FeatureForm из коробочной сборки Docker, которая включает провайдеров Postgres и Redis. FeatureForm используется здесь для препроцессинга датасета и сохранения его для последующего использования в задаче машинного обучения. Для демонстрации работы выбран датасет ny-2015-street-tree-census-tree-data.
Итоговый отчет на странице FeatureStore.
Документацию проекта в удобном для изучения виде смотрите на Gitlab Pages — обновление сайта синхронизировано с обновлением репозитория.