Отчет по заданию MLflow
Применен базовый фнукционал MLflow в задаче версионирования эксперимента для двух различных ML-моделей. Выполнялась сравнительная задача машинного обучения по классификации отзывов из датасета Amazon reviews (оценка сентимента).
Ноутбуки с исследованиями:
- Модель №1: Частотный анализ на базе TF-IDF
- Модель №2: Эмбеддинг на базе Bert Transformer
Для выполнения задачи был запущен локальный MLflow инстанс, проведен сравнительный эксперимент для выбранных моделей, после чего зафиксированы результаты и составлен данный отчет.
В ноутбуках использовался фреймворк Hydra для загрузки параметров.
Подготовка среды
Пример настройки среды для conda/mamba:
mamba create -y -n mlflow python=3.10.14 numpy pandas polars nltk scikit-learn matplotlib mlflow hydra-core omegaconf pytorch transformers ipykernel
Запуск локального инстанса MLflow
Необходимо запустить в отдельной консоли локальный сервер MLflow перед запуском скриптов:
mlflow server --host 127.0.0.1 --port 8080
Трекинг экспериментов
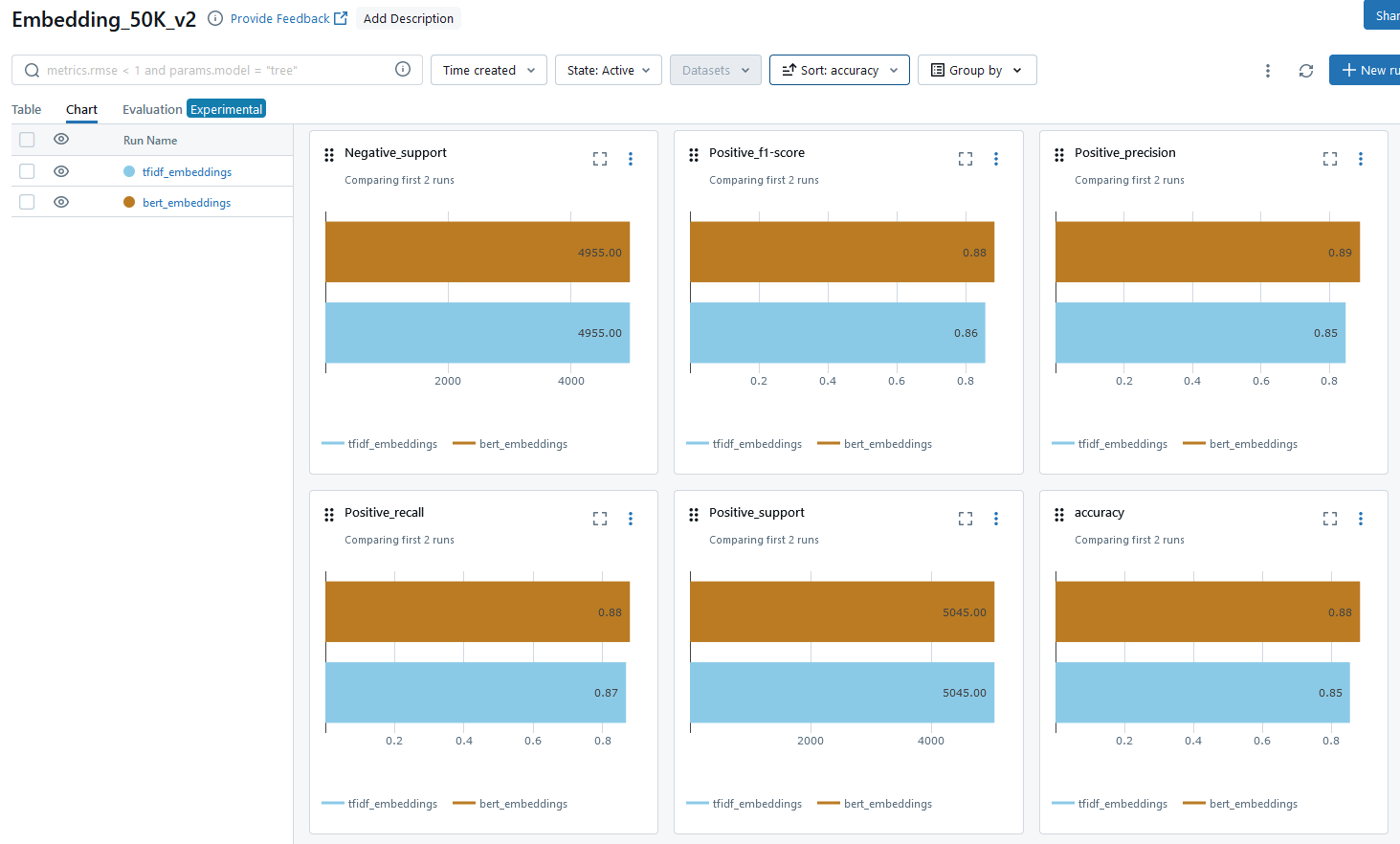
Ниже некоторые скриншоты из веб-интерфейса MLflow после завершения сравнительных эксприментов. Из данных ниже можно сделать вывод, что модель с эмбеддингом на базе Bert Transformer дает лучшие результаты по всем параметрам.
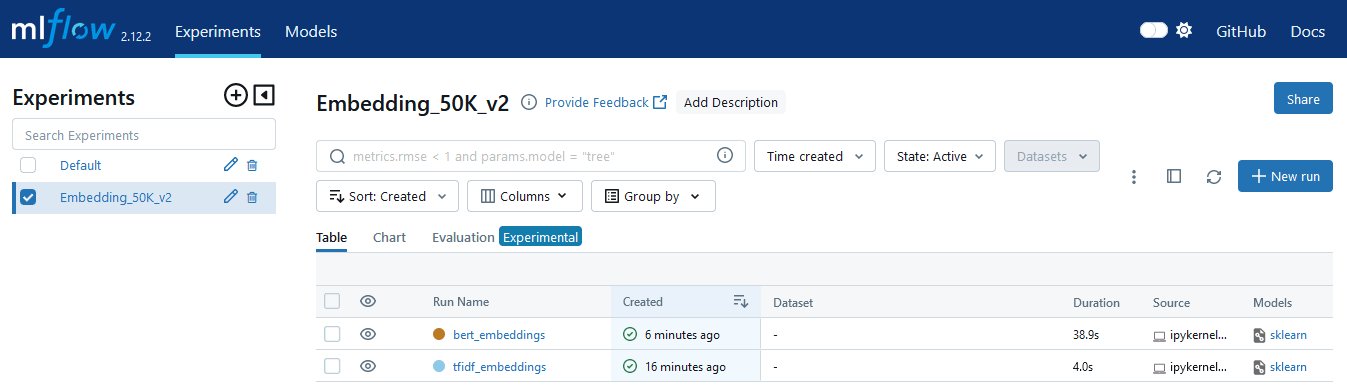
Общий вид раздела экспериментов в MLflow после их проведения:
MLflow предлагает удобное визуальное сравнение для результатов нескольких экспериментов, например:
Пример сохранения артефактов для одной из моделей:
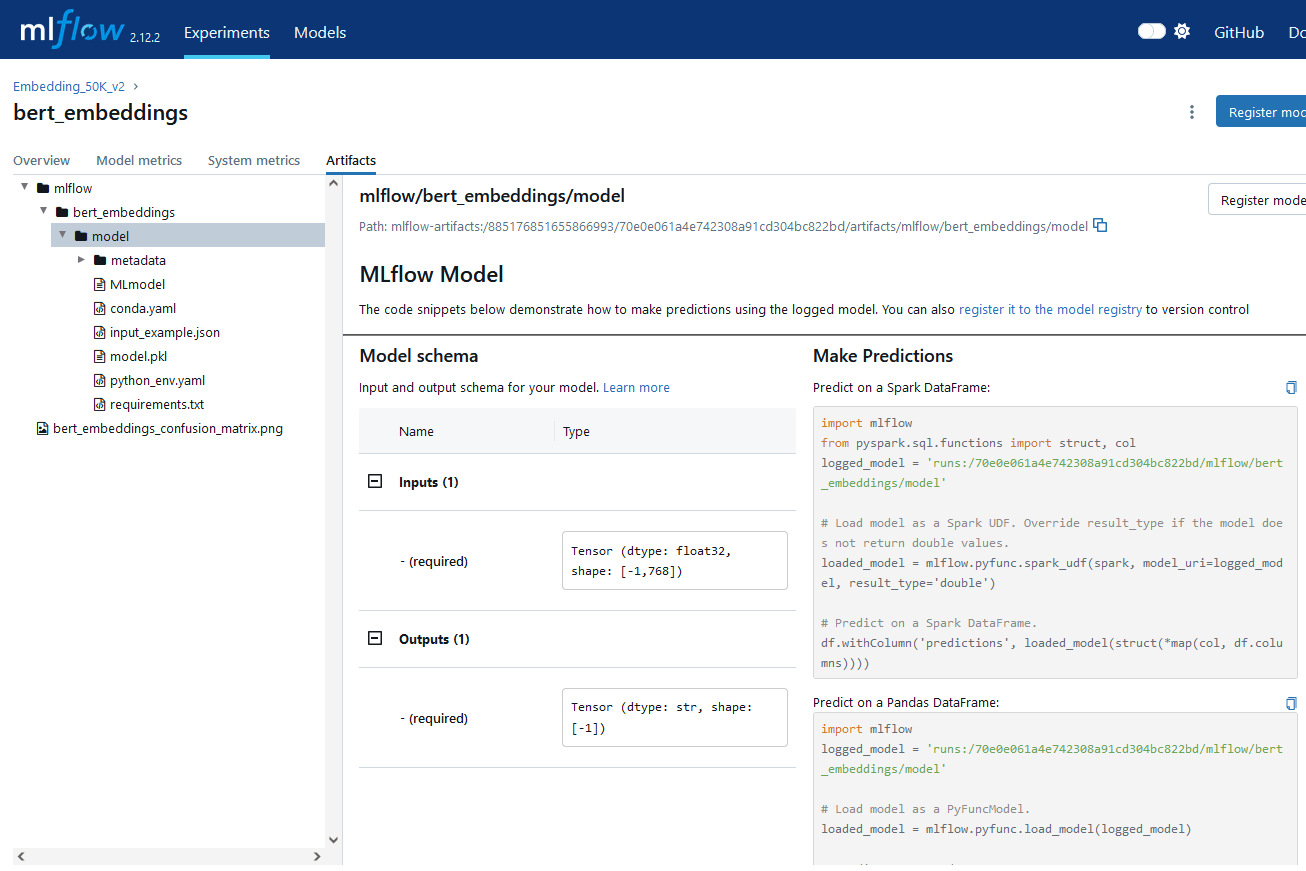
Артефакты тренировки моделей
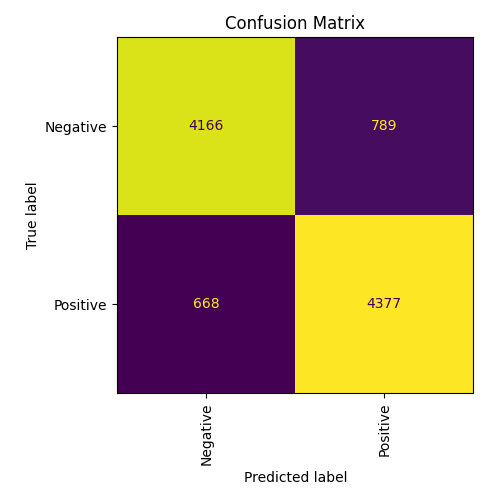
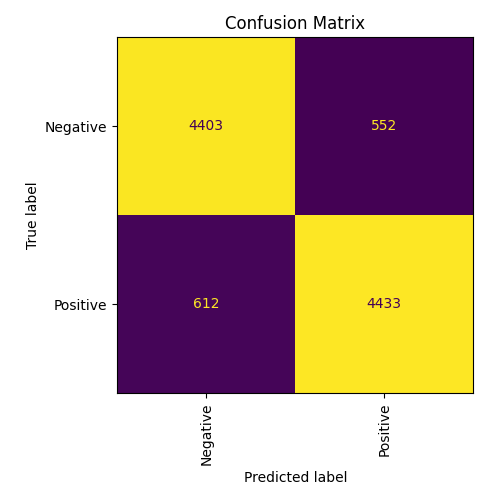
Confusion matrix для TF/IDF слева, для Bert справа: