Отчет по заданию Snakemake
Объяснение реализации
Реализован следующий worlkflow (см. Snakefile):
Препроцессинг данных, объединяющий csv-файлы в папках поочередно по шаблонам:
data/01/*.csv,data/02/*.csv,data/03/*.csv.Сформированный датасет подается на вход скрипта trees-training-workflow.py с демонстрационным обучением ML-модели. Каждый запуск скрипта сгенерировал и сохранил артефакты с результатами.
Пайплайн Snakemake запускался с использованием виртуальной среды conda с пакетами Scikit-learn, Tensorflow и др. Команды подготовки среды и запуска:
conda env export -n ml -f .envs/ml.yml
snakemake --use-conda --conda-prefix ./.envs --cores 4DAG
Изображение для визуализации DAG было сформировано командой:
snakemake --dag | dot -Tsvg > dag.svg

Сформированные пакеты данных
Из папки
data/01/*.csvбыло объединено в data/compiled-data-01.csvИз папки
data/02/*.csvбыло объединено в data/compiled-data-02.csvИз папки
data/03/*.csvбыло объединено в data/compiled-data-03.csv
Артефакт обучения ML-модели
Артефакт создан как часть workflow процесса обработки данных. Обучение модели носит демонстрационный характер.
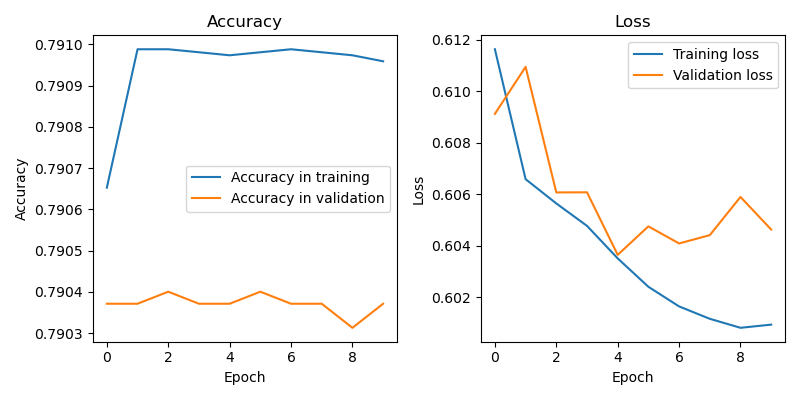
Входной файл: data/compiled-data-01.csv
Достигнутая точность: 0.791

Артефакт обучения ML-модели
Артефакт создан как часть workflow процесса обработки данных. Обучение модели носит демонстрационный характер.
Входной файл: data/compiled-data-02.csv
Достигнутая точность: 0.851

Артефакт обучения ML-модели
Артефакт создан как часть workflow процесса обработки данных. Обучение модели носит демонстрационный характер.
Входной файл: data/compiled-data-03.csv
Достигнутая точность: 0.787